LlamaIndex 初探
背景
将大语言模型运用在个人数据上,一个用于实现RAG的框架
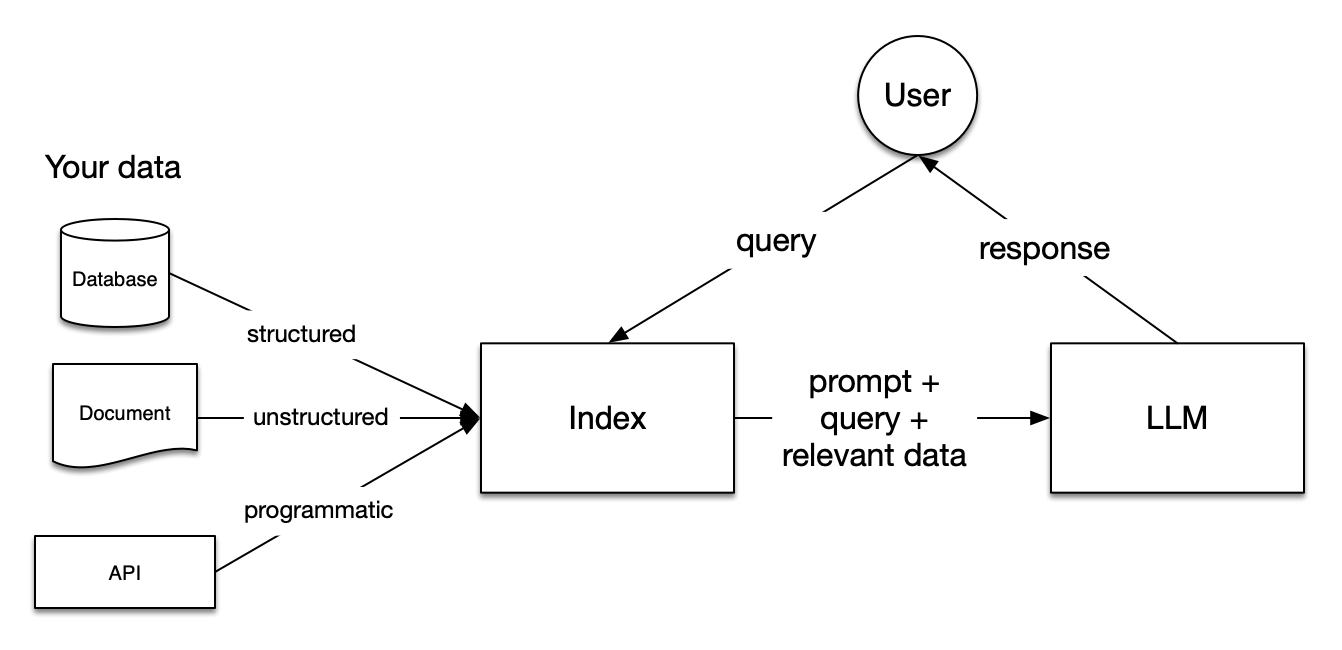
LlamaIndex serves as a bridge between your data and Large Language Models (LLMs), providing a toolkit that enables you to establish a query interface around your data for a variety of tasks, such as question-answering and summarization.
落地
演示
安装准备
pip install llama-index
# 如果使用OpenAI 需要设定环境变量(当前默认使用OpenAI)
export OPENAI_API_KEY=XXXXX
最基础的演示
# indexing 以及 LLM请求 均包装在内部 且 默认使用了OpenAI
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
# 增加了Index的缓存逻辑
if not os.path.exists("./storage"):
# 所有文档存放在data目录下,支持一个和多个,进行加载和索引构建
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist()
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)
# either way we can now query the index
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
# 下方会有如何使用自定义模型的介绍
PS:日志查看
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# logging.INFO or logging.DEBUG ...
逻辑
基础流程:加载数据-构建索引-索引存储-检索-评估
自定义
使用特定的LLM
from llama_index import ServiceContext
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
)
from llama_index.llms import PaLM
service_context = ServiceContext.from_defaults(llm=PaLM())
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
query_engine = index.as_query_engine(service_context=service_context)
基于 Ollama 以及 Langchain 使用 LlamaIndex 串起一个 RAG 在本地使用 ⭐️
使用下来在英文文档上效果较好,中文场景效果一般,估计和中间环节Prompt是英文的,以及llama系列模型在英文上支持较好有关系
注: 使用 Langchain 来加载 Ollama 中的 Embedding 比较方便 ,且 LlamaIndex 中也兼容
from llama_index import ServiceContext
from llama_index.llms import Ollama
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
)
from langchain.embeddings import OllamaEmbeddings
oembed = OllamaEmbeddings(base_url="http://localhost:11434", model="mistral")
llm_ollama = Ollama(model="mistral")
# https://docs.llamaindex.ai/en/stable/module_guides/models/embeddings.html
service_context = ServiceContext.from_defaults(embed_model=oembed,llm = llm_ollama,chunk_size = 1000)
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
query_engine = index.as_query_engine(service_context=service_context)
使用自定义数据切块
from llama_index import ServiceContext
# 原本
index = VectorStoreIndex.from_documents(documents)
# 自定义 手动输入 service_context
service_context = ServiceContext.from_defaults(chunk_size=1000)
# =================== 或者 ==========================
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
service_context = ServiceContext.from_defaults(text_splitter=text_splitter)
# =================================================
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
每次返回更多的结果
query_engine = index.as_query_engine(similarity_top_k=5)
可以定义 response_mode , 内部是基于不同的prompt对结果进行了一些加工(比如结构化、总结等等)
query_engine = index.as_query_engine(response_mode="tree_summarize")
可以将结果按照streaming模式输出
query_engine = index.as_query_engine(streaming=True)
response = query_engine.query("What did the author do growing up?")
response.print_response_stream()
# 另一个代码模式
chat_engine = index.as_chat_engine()
streaming_response = chat_engine.stream_chat("Tell me a joke.")
for token in streaming_response.response_gen:
print(token, end="")
对话模式 (know more)
query_engine = index.as_chat_engine()
response = query_engine.chat("What did the author do growing up?")
print(response)
response = query_engine.chat("Oh interesting, tell me more.")
print(response)'
'
# Reset chat history to start a new conversation:
chat_engine.reset()
# Enter an interactive chat REPL:
chat_engine.chat_repl()
# 进一步可以指定 chat_mode 有 best / condense_question / context / condense_plus_context / simple 等
读取 Obsidian 的数据 (更多其他数据源可参考 LlamaHub)
from llama_index import download_loader
import os
ObsidianReader = download_loader('ObsidianReader')
documents = ObsidianReader('/path/to/dir').load_data() # Returns list of documents
类似GPTs一样基于LlamaIndex使用自然语言构建 RAG
- https://github.com/run-llama/rags
一些摘录
关于对话的不错的Prompt
custom_prompt = PromptTemplate(
"""\
Given a conversation (between Human and Assistant) and a follow up message from Human, \
rewrite the message to be a standalone question that captures all relevant context \
from the conversation.
<Chat History>
{chat_history}
<Follow Up Message>
{question}
<Standalone question>
"""
)