Retrieval Augmented Generation (RAG)
一句话总结:大模型与信息检索的结合
背景
RAG 早在 GPT 等 LLMs 出来之前就有了相关的研究 。例如 FaceBook 在 2020 年的研究尝试 ,将模型知识分为两类 参数记忆(内部信息) 和 非参记忆(外部信息) ,基于这些知识来产出内容
RAG方式有其灵活性,即使模型参数不变也能适应快速变化的外部信息
外部数据可以是文档、数据库、网页信息、个人知识库、日志、图文视频也可以是从API获取的数据等等
这些外部信息的处理方式通常是切块然后做向量化表征然后在向量数据库中基于用户输入做检索
PS:向量数据库只是一种候选,还可以有更多选择,可以泛化为一个信息检索系统
大模型使用外部数据可以提供更准确和及时的回复,同时减少模型猜测输出的可能性即幻觉,增强用户的信任度
PS:有研究者指出幻觉是让大模型产出创意的基础,现在大家都在思考如何消除幻觉,其实另一个方向也可做利用
目前看来,RAG 是当前大语言模型场景下最有效的整合最新可验证信息的方式,且无需重新训练和更新以保持较小成本
Simply upload the latest documents or policies, and the model retrieves the information in open-book mode to answer the question.
落地
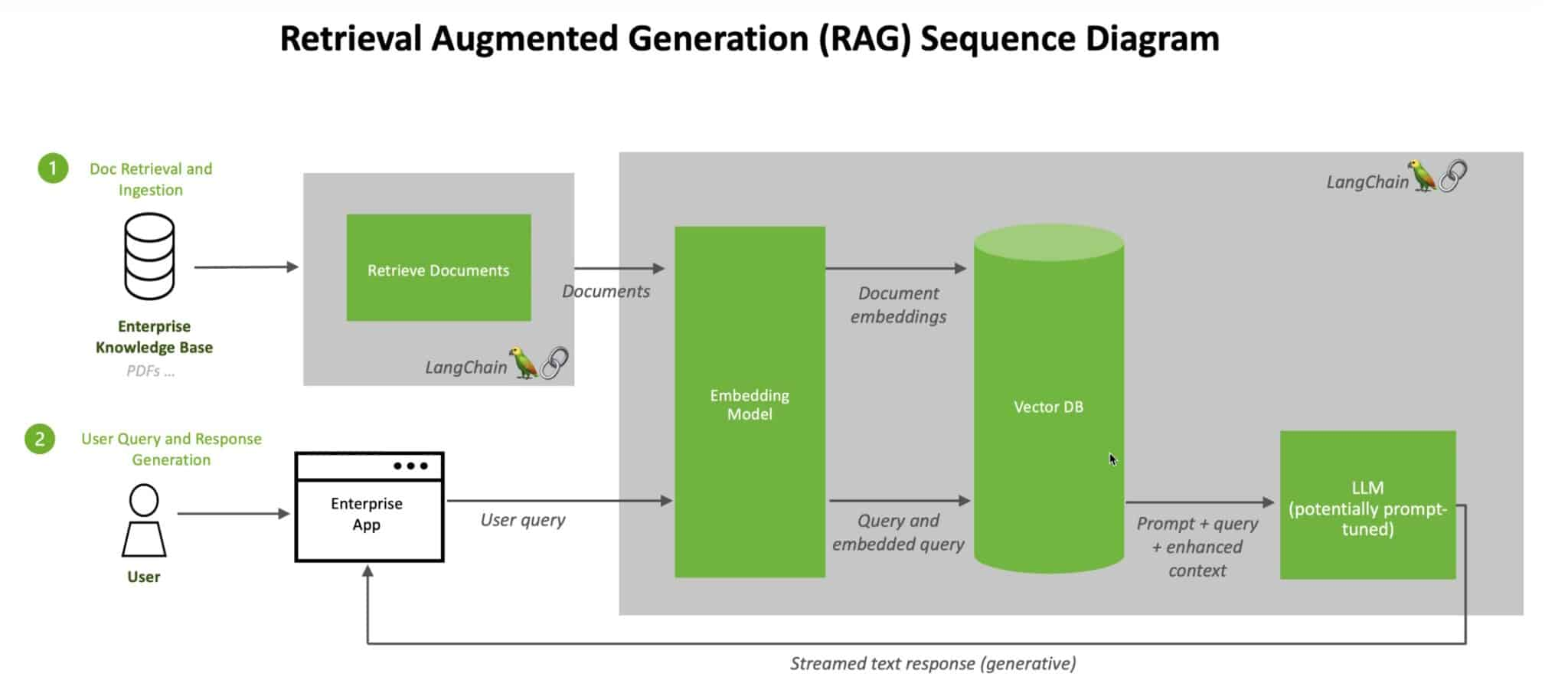
一个典型的RAG包含两个主要的部分(和信息检索很像)
- 索引构建
- 数据准备和加载
- 将数据划分成小的数据块(这样能更好的做索引以及输入到后续的模型中)
- 数据块之间最好保留一些重合
- 例如将数据划分成1000个字符大小的数据块,相邻数据块之间有200个字符重合
- 默认先用通用分隔符例(如换行符)来分割,直到每个块的大小合适
- 将原始数据做向量表征存储,方便后续做语义检索
- 检索和生成
- 基于用户输入,检索出相关的数据
- 可进一步研究如何竟可能的检索出最相关的信息
- 使用包含检索数据的prompt去生成回答
- 可进一步研究如何组织和整合这些信息去生成最佳的回答
- 基于用户输入,检索出相关的数据
场景
- 个人
- 在本地机器上运行LLMs,将个人的笔记、文件、邮件等作为外部信息,基于RAG能构建很好的个人助理,并且保持数据的隐私性
- 企业
- 各种需要包含数据的专业领域
可使用的技术
- Langchain
- LlamaIndex
- LlamaIndex is a data framework for LLM-based applications to ingest, structure, and access private or domain-specific data.
工具选择的建议
Langchain is a more general-purpose framework that can be used to build a wide variety of applications. It provides tools for loading, processing, and indexing data, as well as for interacting with LLMs. Langchain is also more flexible than LlamaIndex, allowing users to customize the behavior of their applications.
LlamaIndex is specifically designed for building search and retrieval applications. It provides a simple interface for querying LLMs and retrieving relevant documents. LlamaIndex is also more efficient than Langchain, making it a better choice for applications that need to process large amounts of data.
If you are building a general-purpose application that needs to be flexible and extensible, then Langchain is a good choice. If you are building a search and retrieval application that needs to be efficient and simple, then LlamaIndex is a better choice.
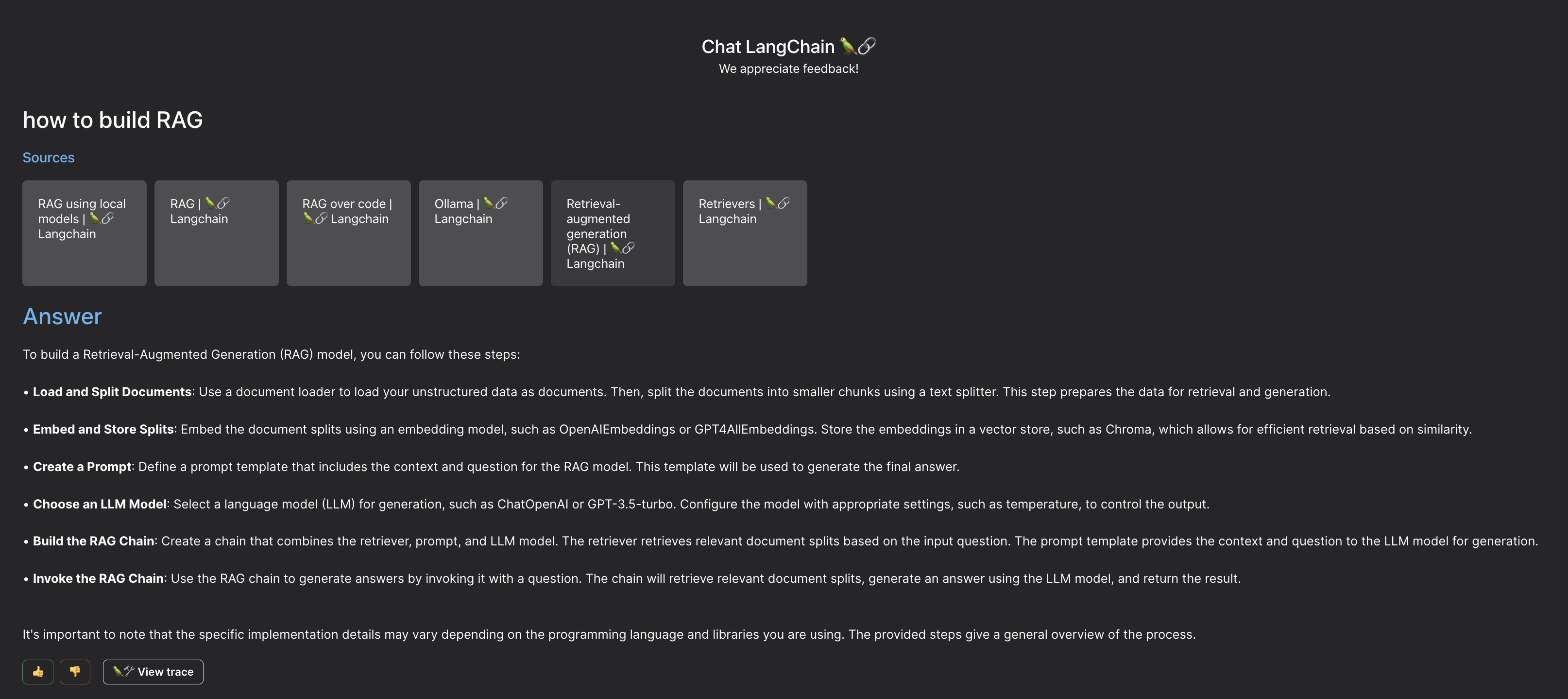
案例
通过 Chat LangChain 可以尝试 RAG的落地效果
一些摘录
定义
RAG is a technique for augmenting LLM knowledge with additional, often private or real-time, data.
Retrieval-augmented generation (RAG) is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLM’s internal representation of information.
Retrieval-augmented generation (RAG) is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources.
Retrieval Augmentation Generation (RAG) is an architecture that augments the capabilities of a Large Language Model (LLM) like ChatGPT by adding an information retrieval system that provides grounding data.
杂谈
In a 2020 paper, Meta (then known as Facebook) came up with a framework called retrieval-augmented generation to give LLMs access to information beyond their training data. RAG allows LLMs to build on a specialized body of knowledge to answer questions in more accurate way.
Given the prompt “When did the first mammal appear on Earth?” for instance, RAG might surface documents for “Mammal,” “History of Earth,” and “Evolution of Mammals.” These supporting documents are then concatenated as context with the original input and fed to the seq2seq model that produces the actual output.
Retrieval-augmented generation gives models sources they can cite, like footnotes in a research paper, so users can check any claims. That builds trust.
What’s more, the technique can help models clear up ambiguity in a user query. It also reduces the possibility a model will make a wrong guess, a phenomenon sometimes called hallucination.
RAG thus has two sources of knowledge: the knowledge that seq2seq models store in their parameters (parametric memory) and the knowledge stored in the corpus from which RAG retrieves passages (nonparametric memory).
An LLM’s parameters essentially represent the general patterns of how humans use words to form sentences.
That deep understanding, sometimes called parameterized knowledge, makes LLMs useful in responding to general prompts at light speed. However, it does not serve users who want a deeper dive into a current or more specific topic.
RAG’s true strength lies in its flexibility. Changing what a pretrained language model knows entails retraining the entire model with new documents. With RAG, we control what it knows simply by swapping out the documents it uses for knowledge retrieval.
RAG allows NLP models to bypass the retraining step, accessing and drawing from up-to-date information and then using a state-of-the-art seq2seq generator to output the results.
For more complex and knowledge-intensive tasks, it's possible to build a language model-based system that accesses external knowledge sources to complete tasks. This enables more factual consistency, improves reliability of the generated responses, and helps to mitigate the problem of "hallucination".
The process of bringing the appropriate information and inserting it into the model prompt is known as Retrieval Augmented Generation (RAG).
RAG also reduces the need for users to continuously train the model on new data and update its parameters as circumstances evolve.
“Think of the model as an overeager junior employee that blurts out an answer before checking the facts,” said Lastras. “Experience teaches us to stop and say when we don’t know something. But LLMs need to be explicitly trained to recognize questions they can’t answer.”
When the LLM failed to find a precise answer, it should have responded, “I’m sorry, I don’t know,” said Lastras, or asked additional questions until it could land on a question it could definitively answer.
RAG is currently the best-known tool for grounding LLMs on the latest, verifiable information, and lowering the costs of having to constantly retrain and update them.
By using RAG on a PC, users can link to a private knowledge source – whether that be emails, notes or articles – to improve responses. The user can then feel confident that their data source, prompts and response all remain private and secure.
With RAG, the external data used to augment your prompts can come from multiple data sources, such as a document repositories, databases, or APIs. The first step is to convert your documents and any user queries into a compatible format to perform relevancy search.
A query's response provides the input to the LLM, so the quality of your search results is critical to success.
To understand RAG, we must first understand semantic search, which attempts to find the true meaning of the user’s query and retrieve relevant information instead of simply matching keywords in the user’s query. Semantic search aims to deliver results that better fit the user’s intent, not just their exact words.
Retrieval Augmented Generation (RAG) has become an essential component of the AI stack. RAG helps us reduce hallucinations, fact-check, provide domain-specific knowledge, and much more.
参考
- 2020.05.22 | Paper | Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- 2022.09.28 | Retrieval Augmented Generation in Meta
- 2023 | Retrieval Augmented Generation (RAG)
- 2023 | Retrieval-augmented generation (RAG) in LangChain
- 2023 | RAG using local models in LangChain
- 2023.02.05 | Tutorial: ChatGPT Over Your Data in LangChain
- 2023 | RETRIEVAL AUGMENTED GENERATION in LangChain
- 2023 | Retrieval in LangChain
- 2023.08.22 | What is retrieval-augmented generation? in IBM
- 2023.11.15 | What Is Retrieval-Augmented Generation aka RAG? in NVIDIA
- 2023 | Retrieval Augmented Generation (RAG) in AWS
- 2023.11.20 | Retrieval Augmented Generation (RAG) in Azure AI Search
- 2023 | Retrieval Augmented Generation (RAG): The Solution to GenAI Hallucinations in Pinecone
- 2023 | Retrieval Augmented Generation in Pinecone
- 2023.08.23 | YouTube | What is Retrieval-Augmented Generation (RAG)? In IBM / YouTube Video
- 2023.07.29 | YouTube | Better Llama 2 with Retrieval Augmented Generation (RAG)
- 2023.10.30 | Comparison of LLamaIndex and LangChain
- 2023 | We can use Olama with RAG in LangChain
- 2023 | Retrieval Augmented Generation (RAG) in Llamaindex